Overview
Path-Coupled Bellman Flows (PCBF) is a continuous-time distributional reinforcement learning method that learns return distributions with flow matching using source-consistent Bellman-coupled paths: the current path starts from the required base prior at $t{=}0$, reaches the Bellman target at $t{=}1$, and maintains a pathwise affine relation to the successor flow at intermediate times. PCBF couples current and successor return flows through shared base noise and uses a $\lambda$-parameterized control variate that trades controlled bias for variance reduction in critic training.
Accepted at ICML 2026 as a regular-track presentation.

Animated Demo
The animation below visualizes learned return transport on the Discrete Monte Carlo toy environment: particles flow from a Gaussian source at $t{=}0$ to the learned return distribution at $t{=}1$ along PCBF Bellman-coupled trajectories.
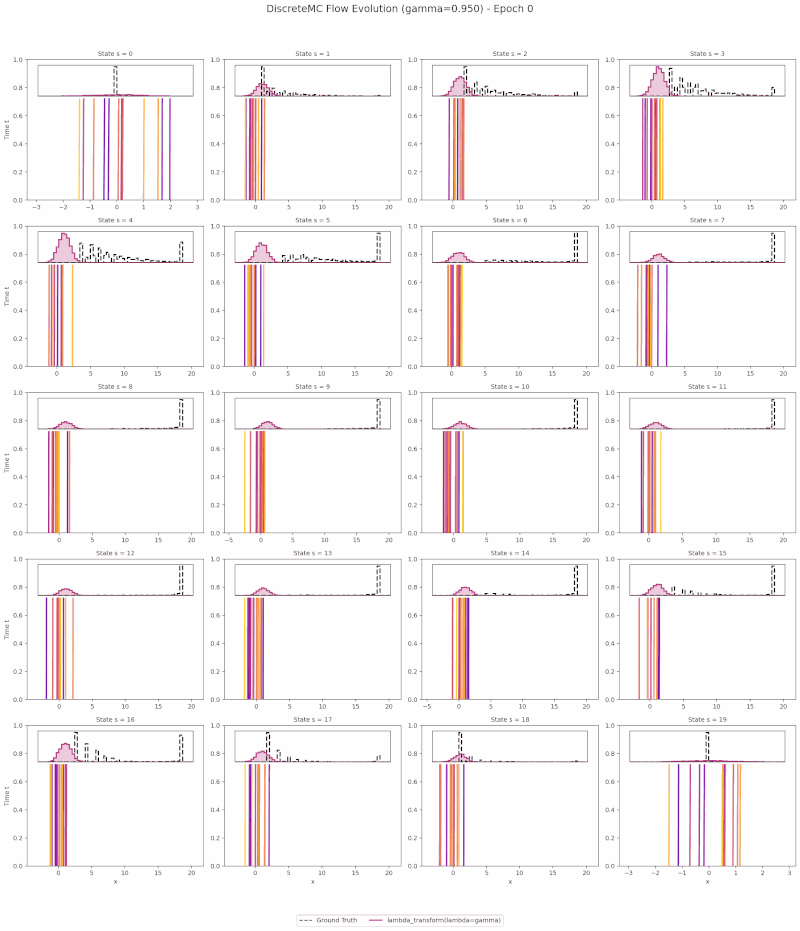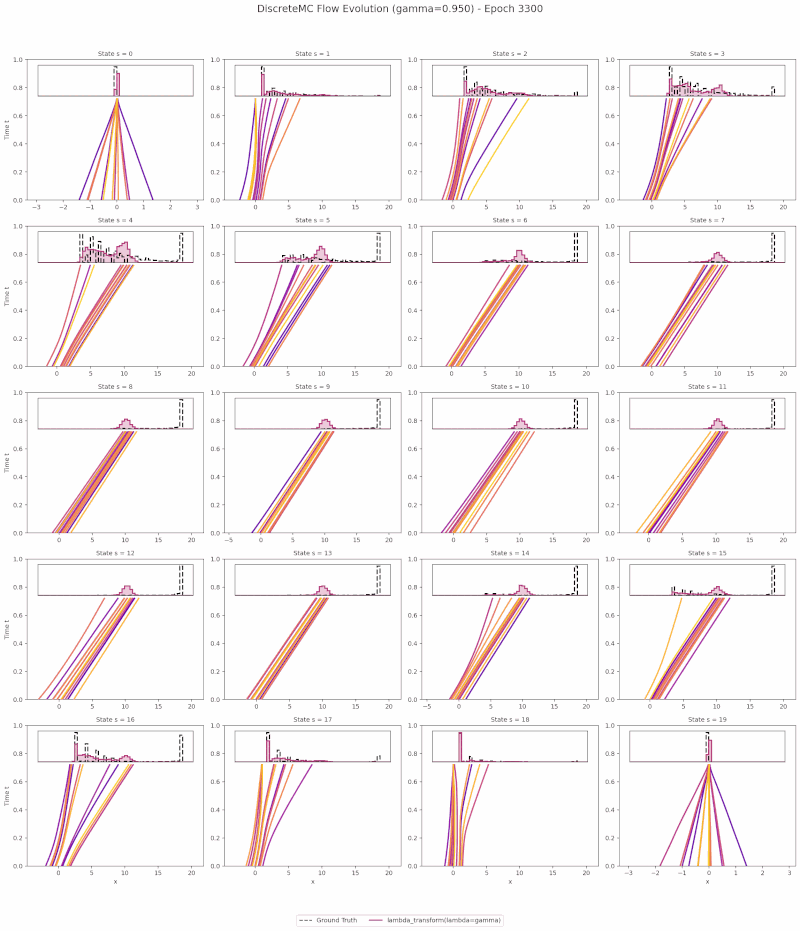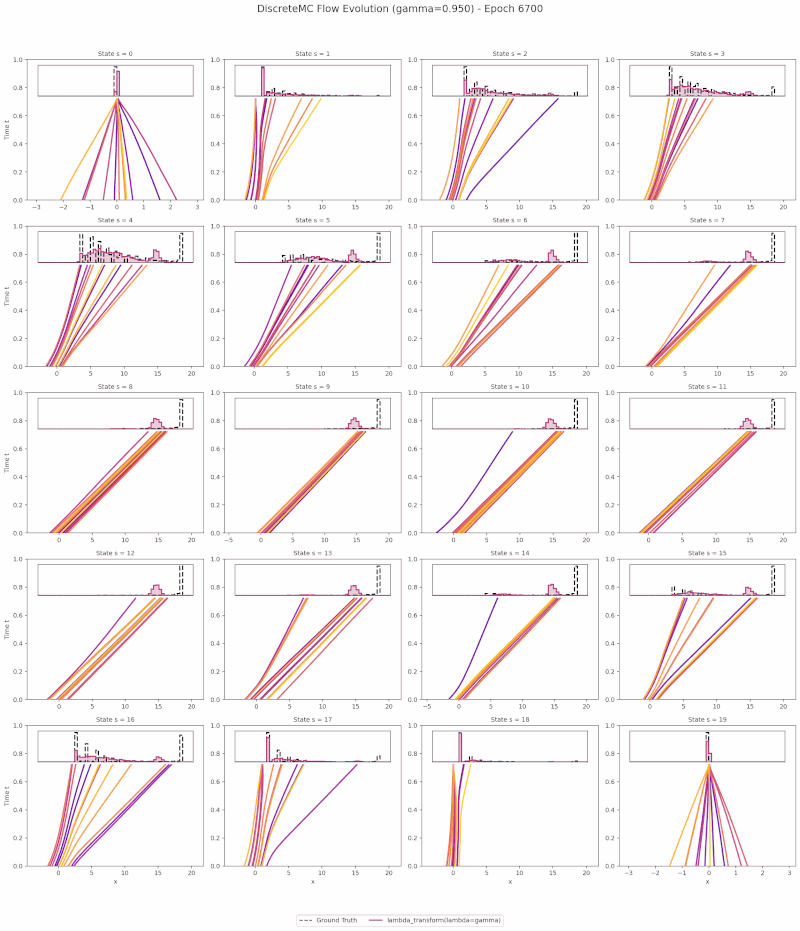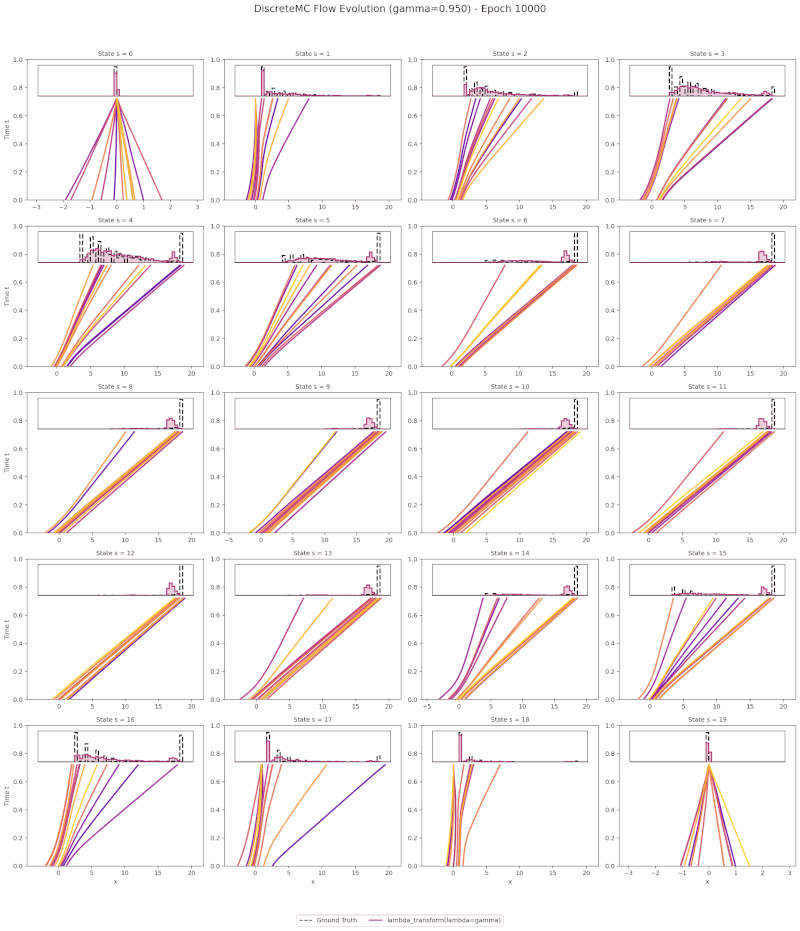
Motivation
Distributional reinforcement learning (DRL) models the full distribution of returns rather than only their expectation, enabling richer uncertainty representations and often better empirical performance. Most practical DRL algorithms, however, rely on finite-dimensional approximations — categorical projections or quantile assignments — that introduce bias when the Bellman update does not align with fixed support points.
Reframing DRL as continuous probability transport makes flow matching a natural framework: the distributional Bellman equation defines an affine transport relationship, and a neural velocity field can transport samples from a simple Gaussian prior to the return law without heuristic projections.
Directly enforcing an uncorrected pointwise Bellman map inside flow composition fails in two critical ways:
- Source boundary mismatch. Flow matching requires generation to start from a fixed simple prior (e.g., $\mathcal{N}(0,1)$), but an uncorrected Bellman update $Z_t = R + \gamma Z'_t$ starts from $R + \gamma X_0 \neq X_0$.
- High-variance bootstrapping. When current and successor noises are sampled independently, intermediate trajectories are not pathwise aligned; Bellman consistency can only be enforced at the endpoint, yielding unstable per-sample targets.
PCBF resolves both issues through source-consistent Bellman path correction and shared-noise path coupling, cleanly separating geometric flow requirements from Bellman bootstrapping variance.
Method: Path-Coupled Bellman Flows
Shared-noise Bellman paths
Given shared base noise $X_0 \sim \mathcal{N}(0,1)$ and a successor return sample $X' = \psi_{\theta^-}^{1}(X_0 \mid s', a')$ from the target flow map, PCBF defines time-synchronized linear interpolation paths:
$$ Z^{s'}_t = (1-t)X_0 + t X' \qquad\text{(successor path)}, $$ $$ Z^{s}_t = (1-t)X_0 + t\bigl(R + \gamma X'\bigr) \qquad\text{(current path)}. $$An equivalent form that reveals the Bellman geometry is:
$$ Z^s_t = t R + \gamma Z^{s'}_t + (1-t)(1-\gamma)X_0. $$The residual anchor $(1-t)(1-\gamma)X_0$ guarantees exact alignment at $t{=}0$ regardless of $\gamma$, while $Z^s_1 = R + \gamma X'$ satisfies the distributional Bellman boundary at $t{=}1$. Differentiating yields the unbiased BCFM target $\dot Z^s_t = R + \gamma X' - X_0$.
Lambda-parameterized control variates
To reduce variance from the noisy successor sample $X'$, PCBF forms the training target $u_t^\lambda$ from two pieces:
- Sample Bellman velocity (baseline): $Y = R + \gamma X' - X_0$. This is unbiased but can have high variance because it depends directly on the bootstrapped successor return $X'$.
- Control-variate correction: $\lambda \cdot \bigl( v_{\theta^-}(t, Z^{s'}_t \mid s', a') - (X' - X_0) \bigr)$, where $v_{\theta^-}$ is the lagged target velocity field along the successor path $Z^{s'}_t$.
Putting them together,
$u_t^\lambda = Y + \lambda \bigl( v_{\theta^-}(t, Z^{s'}_t \mid s', a') - (X' - X_0) \bigr)$.
Setting $\lambda = 0$ recovers the unbiased sample Bellman target. Values $\lambda > 0$ introduce a variance-reducing correction using successor-flow velocity predictions. With shared-noise coupling, the induced bias stays small: in a linear–Gaussian model, shared noise ($\rho = 1$) gives bias on the order of $(1-\gamma)(1-t)$, which vanishes when $\gamma \approx 1$ and at the flow endpoints $t \in \{0, 1\}$.
Policy extraction for offline RL
At deployment, a behavior-cloned proposal policy samples $K{=}16$ candidate actions; each is scored by the mean terminal return under the learned flow $\hat Q_\theta(s,a) = \frac{1}{M}\sum_m \psi_\theta^{1}(X_{0,m}\mid s,a)$, and the highest-scoring action is executed.
Toy Environments: Distributional Fidelity
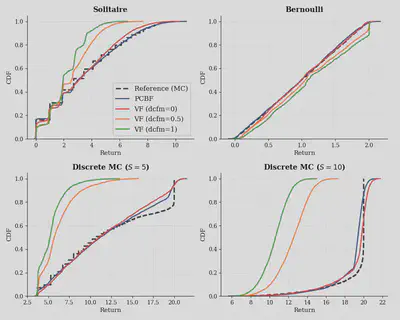
We validate PCBF on three analytically tractable environments with known return laws: Solitaire Dice (heavy-tailed discrete returns), Bernoulli MRP (uniform return on $[0,2]$), and Discrete Monte Carlo Chain (multimodal finite-horizon returns).
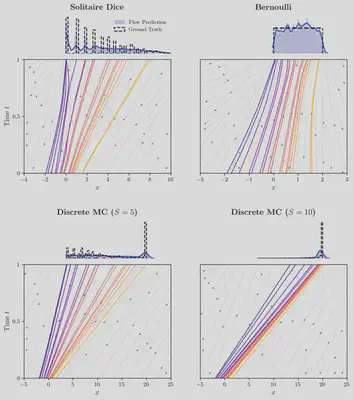

Pathwise Bellman Residual and Discretization
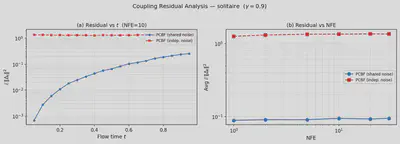
PCBF enforces the Bellman endpoint at $t{=}1$ by construction, but training uses a finite-step Euler solver (10 NFE). Shared-noise coupling yields smaller corrected Bellman residuals $r_{\mathrm{corr}}(t,N)$ than independent-noise ablations across solver budgets $N \in \{4,8,16,32\}$:
Offline RL Benchmarks
We evaluate PCBF on 38 offline RL tasks: 30 OGBench single-task variants (four state-based manipulation domains and two pixel-based domains) plus eight D4RL Adroit tasks. Baselines include distributional methods (IQN, CODAC, Value Flows), flow-based scalar critics (FloQ, FQL), and IQL.
Aggregated results
| Domain | IQN | CODAC | FloQ | FQL | IQL | Value Flows | PCBF (Ours) |
|---|---|---|---|---|---|---|---|
| cube-double-play (5 tasks) | 42 ± 8 | 61 ± 6 | 47 ± 14 | 29 ± 6 | 7 ± 1 | 69 ± 4 | 71 ± 5 |
| scene-play (5 tasks) | 40 ± 1 | 55 ± 1 | 58 ± 4 | 56 ± 2 | 28 ± 3 | 59 ± 4 | 54 ± 4 |
| puzzle-4×4-play (5 tasks) | 27 ± 4 | 20 ± 18 | 28 ± 6 | 17 ± 5 | 7 ± 2 | 27 ± 4 | 30 ± 4 |
| cube-triple-play (5 tasks) | 6 ± 0 | 2 ± 1 | 8 ± 3 | 4 ± 2 | 1 ± 1 | 14 ± 3 | 4 ± 1 |
| D4RL adroit (8 tasks) | 66 ± 5 | 69 ± 0 | 70 ± 5 | 71 ± 4 | 70 | 65 ± 2 | 69 ± 2 |
| visual-antmaze-teleport (5 tasks) | 4 ± 2 | — | — | 5 ± 2 | 6 ± 4 | 13 ± 4 | 14 ± 4 |
| visual-cube-double-play (5 tasks) | 1 ± 0 | — | — | 6 ± 1 | 11 ± 6 | 13 ± 2 | 3 ± 0 |
Takeaways.
- Selective but strong gains. PCBF achieves best or near-best aggregate performance on cube-double-play, puzzle-4×4-play, D4RL Adroit, and visual-antmaze-teleport, where critic-side return-law fidelity and variance-controlled bootstrapping affect action ranking.
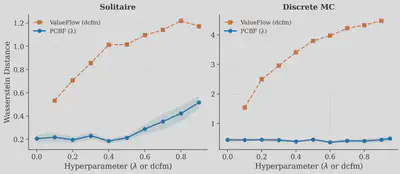
- Best distributional fidelity on toys. On analytically tractable MRPs, PCBF closely tracks ground-truth CDFs and remains robust to $\lambda$, while Value Flows degrades as the DCFM consistency weight increases.
- Honest limitations. On cube-triple-play and visual-cube-double-play, PCBF underperforms Value Flows — long-horizon sparse-reward and pixel-based settings remain challenging when policy extraction, visual encoders, or $\lambda$ selection become bottlenecks.
- Similar cost to Value Flows. PCBF uses ~60 GB GPU memory and ~2.5× wall-clock versus scalar critics on OGBench (single A100, $10^6$ steps); training requires 10-step Euler integration of the velocity field.
Key Contributions
- Source-consistent Bellman-interpolated paths that resolve the $t{=}0$ boundary mismatch of uncorrected pointwise Bellman paths while preserving the Bellman endpoint at $t{=}1$.
- Shared-noise path coupling that aligns current and successor return flows pathwise, inducing a geometric Bellman relation between velocity fields.
- $\lambda$-parameterized control-variate target with a distribution-free $L_2$ bias bound and a linear–Gaussian closed form explaining why shared-noise coupling shrinks intrinsic bias.
- Population velocity identification, shared-noise Bellman contraction, and Euler integration sensitivity analysis supporting stable flow-based distributional critics.
- Comprehensive evaluation on Solitaire Dice, Bernoulli, and Discrete MC toy MRPs plus 38 OGBench and D4RL offline RL tasks.
Quick Start
The reference implementation is available on GitHub: BoyangASU/path-coupled-bellman-flows.
PCBF is implemented in JAX, adapted from the FQL codebase. Key hyperparameters: 10 Euler integration steps, batch size 256, learning rate $3\times10^{-4}$, and domain-tuned $\lambda$ (see paper Tables for per-domain values). State-based tasks train for 1M gradient steps; pixel-based tasks for 500K steps.
Resources
- Paper (arXiv): arXiv:2605.08253
- Code: github.com/BoyangASU/path-coupled-bellman-flows
- Venue: ICML 2026 (regular track)
BibTeX
@inproceedings{xu2026pathcoupled,
title = {Path-Coupled Bellman Flows for Distributional Reinforcement Learning},
author = {Xu, Boyang and Zou, Qing and Yang, Siqin and Yan, Hao},
booktitle = {Proceedings of the International Conference on Machine Learning (ICML)},
year = {2026},
note = {Regular track},
eprint = {2605.08253},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2605.08253}
}